OVERVIEW
POPULAR ARTICLES
Tempting as it is to declare a winner in the LLM wars every week or month (depending on the latest capability demonstrated by Claude or Gemini or ChatGPT), such predictions are a waste of time because of just how fluid the AI landscape is. All we know for sure is that AI is an important foundational technology that is here to stay. To generate returns from it for our clients, nearly four years ago in our Global Compounders Portfolio we invested in multiple layers of the physical infrastructure which undergirds AI.
Source: Prof Karim Lakhani’s Substack
“At the current speed of this race, it’s impossible to predict what will happen in the months and years after these words were written in March 2024. But those future events will be rooted in the designs of a handful of people and the systemic forces they operated in.” – Parmy Olson, “Supremacy: AI, ChatGPT and the Race that Will Change the World” (p. 290).
Every few weeks my colleagues in Marcellus will excitedly discuss the latest, greatest thing that one of the LLMs that are easily available to us can do. So, one week we will read in the media that Claude is managing the “kill chain” in the Iran War whilst the next week our analysts will say that Gemini can do better analysis of a company’s financial statements than a freshly minted graduate. In between such news flow, we will hear an announcement from the CEOs of either Nvidia or Alphabet or Microsoft or Anthropic that AI could replace a significant percentage of knowledge workers in the next few years.
It is but natural for equity investors like us to use such news flow to figure out which of the competing LLMs will win the AI war and thus greatly enrich Marcellus’ clients. However, such forecasting is a waste of time because of just how nascent this industry is and because of how fluid the industry’s dynamics are.
For example, it is not yet clear on what basis the LLMs will compete with each other. Will price be the basis of competition or will it be computing power or is it latency that matters? Neither is it clear whether the same basis for competition will prevail in the retail and in the enterprise market.
Even more fundamentally, it is not obvious whether one LLM will do everything or whether we will have different AI models which excel at doing different things. E.g. some models might be really good at helping us with ideation whereas others might be better at coding and still others might be good at data retrieval.
As Prof Karim Lakhani of Harvard Business School says: “Training and inference economics are still changing quickly. Cost structures remain sensitive to power and infrastructure constraints. High-quality training and feedback data remain contested and unevenly distributed. The field is still discovering new ways to improve reasoning, efficiency, multimodality, and agency. We still do not fully know what the enduring product form of AI systems will be. And rules for access, copyright, liability, and deployment are still unsettled. These are not peripheral variables sitting at the edge of the story — they are the story. Together they keep experimentation alive because firms are not merely optimizing within a fixed game. They are still helping define the game itself.”
So, what can we figure out about AI which will help us generate investment returns?
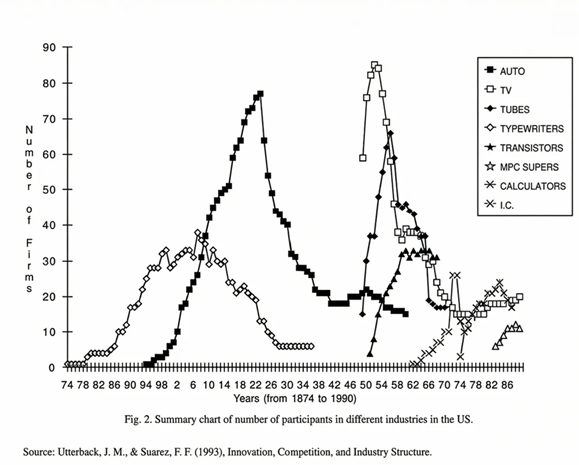
Over 30 years ago, Prof James Utterback of MIT published a study showing that in a range of industries which require significant upfront capex, the same pattern has been observed. Early on the industry tends to be crowded as new players rush in to try their luck. Then after a ‘few’ years (where ‘few’ can mean a couple of decades), new players stop entering. Thereafter, the number of players gradually falls partly because customers start figuring out who is the “best” and partly because some of the stronger players have now built distinctive capabilities that their rivals cannot match. These stronger players then consolidate their position and go on to thrive. All of this happens usually against a backdrop of underlying growth in the industry’s revenues. As the chart above shows, in America, the auto, tyres, typewriter, tubes, transistors and calculator sectors have all followed this pattern.
Applying this model to the LLM providers suggests that we are still in the high-entry phase i.e. where the auto industry was at the dawn of the 20th century. Quoting Prof Lakhani again: “Entry is high, experimentation is intense, and no one has yet been conclusively selected out. It is important to hold two observations separately here. At the architectural level, the field remains genuinely open…But at the firm level, a different dynamic may already be operating quietly underneath the noise — some organizations are accumulating compute, distribution, and organizational learning at a pace that will be hard to replicate later. Architectural openness and competitive asymmetry can coexist in the same moment. The market can still be discovering what it is while some players are already building positions that will matter when it does.
That lens matters for foundation models because it pushes us to ask a more structural question than who currently has the most impressive model. Even if the field eventually converges on something like a dominant design, the deeper industrial question is which organizations can repeatedly finance training runs, secure compute, attract research talent, build data advantages, improve inference economics, create distribution, and turn technical progress into organizational learning….”
Investment implications for our clients
In light of above, nearly four years ago, my colleagues who manage our Global Compounder Portfolio took some important decisions regarding how we will seek to profit from AI:
1. Invest in the critical hardware infrastructure which underpins advanced chip manufacturing ecosystem (rather than investing in Nvidia itself). This led to us investing in ASML and TSMC, among others.
2. Invest in the hyperscale’s who have huge cashflows from their standalone businesses to finance the multi-billion $ spends required to train the LLMs. This led to us investing in Microsoft, Amazon and Alphabet for example. While there are also newer cloud players specialising in AI infrastructure, these typically don’t have large cashflows from existing businesses and need significant external funding (debt or equity) as a result
3. Invest in power generation infrastructure given that a simple AI query requires 10x the power required for a Google search. This led us to invest in Siemens Energy (listed in Germany) for example.
4. Relative to the S&P500, we stay ‘underweight’ on AI as the stockmarket gets caught up in the hype cycle built around a rising number of players and does not factor in what could happen when the consolidation phase will begin.
Whilst we have missed out on Nvidia’s share price surge over the past three years, our investments elsewhere in the ecosystem and supply chain have done well over that time period, thus allowing our clients to benefit from AI without taking on the valuation risks associated with the hype around this foundational technology.
Thanks to the regulatory reforms expedited by the Indian authorities over the past couple of years (see my 7th Jan blog: https://marcellus.in/blogs/four-mega-reforms-which-opened-up-global-investing-for-indians/), you too can now invest in the many layers of the global tech ecosystem a cost-efficient and tax-efficient manner thereby benefitting from this new foundational technology. Our track record in compounding across the world is shown below. Since inception in Oct 2022, the strategy has delivered at ~23% CAGR (net of all fees & expenses in INR). Refer to the chart below.
If you would like more information about our global strategy, please reach out to us at invest@marcellus.in
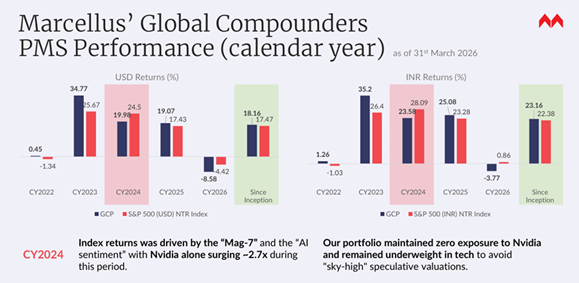
Note: Marcellus performance data is shown gross of taxes and net of fees & expenses charged till end of last month on client account. Performance fees are charged annually in December. Returns more than 1-year are annualized. Marcellus’ GCP USD returns are converted into INR using USD: INR exchange rate from RBI – Link for the reference
Note: * Since Inception performance calculated from 31st Oct 2022. The inception date is 31st Oct 2022, being the next business day after the account got funded on 28th October 2022. S&P 500 net total return is calculated by considering both capital appreciation and dividend payouts. The calculation or presentation of performance results in this publication has NOT been approved or reviewed by the IFSCA or US SEC. Performance is the combined performance of RI and NRI strategies.
Marcellus GCP PMS is offered by Marcellus Investment Managers GIFT Branch in a segregated managed accounts format.
Thanks,
Saurabh Mukherjea
Disclaimer:
The stocks Alphabet, Amazon, Microsoft, ASML, TSMC and Siemens Energy are part of the Global Compounders Strategy managed from GIFT City by Marcellus and regulated by IFSCA. Marcellus, its employees, their relatives, and clients have an interest in these stocks.
This material is for informational purposes only and does not constitute investment advice, an offer, or a solicitation to buy or sell any securities. Past performance is not indicative of future results. All company references are for illustrative purposes only and do not represent recommendations. Projections are based on third‑party sources and may change. Investors should consult their financial advisor before making investment decisions.